link 本题为原T3
题意
给定一个字符串 S,定义 f(S) 为 S 的字典序最小的循环移位。
举个例子,如果 S=babca,那么 f(S)=ababc,因为它是所有循环移位中字典序最小的(包括 babca、abcab、bcaba、cabab、ababc)。
现在给你三个整数 X,Y,Z。
你需要构造一个字符串 T,它恰好包含 X 个 a,Y 个 b,和 Z 个 c。
如果存在多个满足条件的字符串,你想选出一个使得 f(T) 字典序最大。
请计算 f(T) 可能达到的字典序最大值。注意:输出为 f(T)。
1≤X,Y,Z≤105 on gjoj
这篇题解的做法是和其他题解相同的。不同点在于结论推导的过程会在下面给出,因此结论会在最后面。
(其实是我菜,不能一遍推出来)
推导过程
先不考虑某个字符数量为 0 的情况,即 abc 都有。
我们考虑一件事情:由于一定会有最小的字符 a,在循环移位中,肯定会以 a 为 f(T) 的开头。
考虑 T 被 a 拆分成若干个块,对于 f(T) 的选择而言,其一定会选择字典序更小的块在前。
因为每一个块都是以 a 为开头,这是最小的字符。
考虑两个块 S 和 subS,由于 subS 后面紧跟了一个 a,而 S 中除了第一位以外就没有 a 了,因此 subS<S 是能确定在前面的。
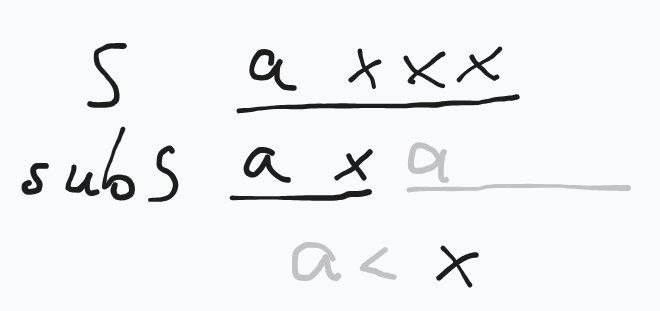
其他不是子串的就不用仔细想了。
因此,想象 X 个底部为 a 的栈,为了保证字典序往大,其他字符肯定会平铺在这 X 个栈中。
我们来模拟看看:
比如当 X=5,Y=7,Z=12 时:

我们考虑将 c 平铺至所有栈中,如下:

显然对于任何 Z,会有 最多能完整铺满的层数 ⌊XZ⌋ 和 最后一层空缺的个数 X−ZmodX。
能平铺完的层自然是不管的,所有 accc…⌊XZ⌋个c… 都是一样的,自然不管了。
关键是有空缺的位置。
根据上面的理论,无论在空缺的位置填充 b 或不填充,这些位置永远都是比其他位置小的。
那么当我们填充 b 的时候,就不需要考虑其他位置了。
如下:
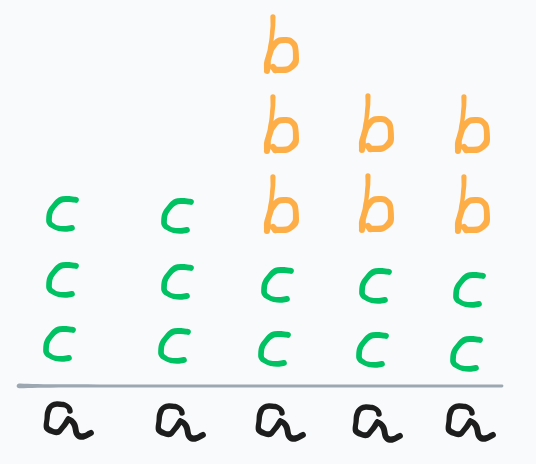
这样我们就完成了块的填充,考虑怎么使它输出了。
一种非常显而易见的想法是先输出最小的块,然后按照字典序倒序输出其余的块。
这样能保证 f(T) 第一个块为最小的同时 f(T) 的字典序最大。
但是这样有问题。
考虑以下两个样例:
-
X=114514,Y=1,Z=2,整理出来为 ac,ac,ab,a,a,a,...,输出为 aacacabaaaaaaaaa
-
X=8,Y=4,Z=4,整理出来为 ac*4,ab*4,输出为 abacacacacababab
显然这里的共性为“有多个相同的最小块”。
两个问题:第一,这样并不是 f(T),因为可以让后面的最小块移到前面,这样才是 f(T)。
第二:这样的构造方式,还有优化空间。
以第二个样例举例,可以构造成 abacabacabacabac,这样显然比 ababababacacacac 更优。
我们不妨设字典序最小的块的字符排列方式为 P。当 f(T) 请求最小的块时,前缀一定为 P。
我们希望使得这些 P 能够尽量大。
考虑这些 P 能够与字典序较大的几个块“拼”在一起,这样会使得这些 P 尽量变大。
将这几个块拼在一起后,重新求最小的 P,重复这个过程,直到 没有较大的块 / P 只有一个。
理1:除非 P 本身已经不存在,不然 P 永远是最小的。
理2:对于较大的块而言,P+ 它们会使它们变小
可以想想这两个理为什么正确,以及理是怎么保证上面的算法正确的。
接下来有几个问题:
Q:为什么要重复这个过程
显然可以构造 X=10,Y=6:aab,aab,aab,aab,ab,ab -> aabab,aabab,aab,aab-> aabaabab,aabaabab
Q:重新求最小的 P 是否会超时
不会。显然重新求的最小的 P 是原来的 P 的子集。
然后就可以实现了…吗?
考虑“较大的块”的集合是否包含 P+较大的块中较大的值,
就是说,能否在没有 除了“新合并的结果”的“较大的块” 的情况下,使用新合并的结果作为 P+ 的对象。
这个结论是一定的,或者说是必须的。
观察到上面 X=10,Y=6,当 P=aab 时,显然如果只使用ab,是不够的。
如果此时退出,显然是不能推到最后面的。
因此后面的两个 aab 应该使用 aabab。
事实上我们可以直接将 P+较大的块中较大的值 与 较大的块中的值 混为一谈。由于 P<较大的块,因此这俩的顺序不用我们刻意强调。
观察到上面两个条件,除了 P 本身,对于 P 其他都可以直接在一个池子里使用了。
那我们就不妨直接使用全部了。
选择所有最小的 P,执行操作:对每一个 P,从池子里拿出一个最大的值 v,将 P+v 重新丢回池子里。直到 没有较大的块 / P 只有一个。
没有较大的块是假的,池子实际上只会通过“选择P”而消耗。其实这样就可以直接 break 掉了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| multiset<string> pool;
string mn;
int cnt;
void print(){
sort(ans+1,ans+x+1);
int k=1;
mn=ans[1];
for(k=2;k<=x;++k){
if(ans[k]!=ans[k-1]) break;
++cnt;
}
for(int i=k;i<=x;++i) pool.insert(ans[i]);
while(cnt>1&&pool.size()){
string nxtmn="z";
int nxtcnt=-114;
for(int i=1;i<=cnt;++i){
auto _end=pool.end();--_end;
string v=*_end;
pool.pop();
pool.insert(mn+v);
if(mn+v<nxtmn){
nxtmn=mn+v;
nxtcnt=1;
}
else ++nxtcnt;
}
pool.erase(mn+v);
mn=nxtmn;cnt=nxtcnt;
}
if(pool.size()==0){
}
else{
}
}
|
到这里为止,已经非常像正解的实现方式了。甚至逻辑都是一样的
正解唯二与这个的区别是:
-
每次查询最小的 P,而不是一次将最小的 P 选完
-
P 只有一个时,和一开始的做法实际上是一样的。因为以 P 为开头的块始终是最小的,就会倒序 cat 掉其余的块。
那么正解就是:从池子里选择最小的 P 和一个最大的值 v,将 P+v 重新丢回池子里。直到池子里只有一个值。
1
2
3
4
5
6
7
8
9
10
11
12
13
| multiset<string> pool;
void print(){
for(int i=1;i<=x;++i) pool.insert(ans[i]);
while(pool.size()>=2){
auto itf=pool.begin(),itb=pool.end();--itb;
string c=(*itf)+(*itb);
pool.erase(itf);
pool.erase(itb);
pool.insert(c);
}
string outputstr=*pool.begin();
printf("%s",outputstr.c_str());
}
|
实际上还能发现一开始,几个块生成的操作也是可以这样得到的。不过我不想解释了,很容易得出来。
最后再把有字符数量为 0 的情况做个归约就好。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
|
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn=1e5+35;
const ll inf=1e18;
ll x,y,z;
ll n;
void single(){
char c=((x==0)?((y==0)?'c':'b'):'a');
for(int i=1;i<=n;++i) putchar(c);
}
string add[maxn];
string ans[maxn];
void solve();
char mapf,mapt;
void _double(){
if(x==0) swap(x,y),mapf='a',mapt='b';
else if(z==0) swap(y,z),mapf='c',mapt='b';
solve();
for(int i=1;i<=x;++i){
ans[i]+=('a'==mapf)?mapt:'a';
for(int j=0;j<add[i].length();++j){
if(add[i][j]==mapf) ans[i]+=mapt;
else ans[i]+=add[i][j];
}
}
}
void triple(){
for(int i=1;i<=x;++i){
ans[i]+='a';
ans[i]+=add[i];
}
}
void print();
void sep(){
int zerocnt=0;
if(x==0) ++zerocnt;
if(y==0) ++zerocnt;
if(z==0) ++zerocnt;
if(zerocnt==3) puts("");
else if(zerocnt==2) single();
else if(zerocnt==1) _double(),print();
else solve(),triple(),print();
}
void solve(){
for(int i=1;i<=z;++i){
int pos=(i%x==0)?(x):(i%x);
add[pos]+='c';
}
ll zmod=z%x,zgap=x-zmod;
ll gapl=x-zgap+1,gapr=x;
for(int i=gapl;i<=gapr;++i){
if(y==0) break;
add[i]+='b';
--y;
}
if(y==0) return;
if(z!=0){
while(1){
for(int i=gapl;i<=gapr;++i){
if(y==0) return;
add[i]+='b';
--y;
}
}
}
else{
for(int i=1;i<=y;++i){
int pos=x-(i%x)+1;
if(pos>x) pos=1;
add[pos]+='b';
}
}
}
multiset<string> que;
void print(){
for(int i=1;i<=x;++i) que.insert(ans[i]);
while(que.size()>=2){
auto itf=que.begin(),itb=que.end();--itb;
string c=(*itf)+(*itb);
que.erase(itf);
que.erase(itb);
que.insert(c);
}
string outputstr=*que.begin();
printf("%s",outputstr.c_str());
}
void reset(){
mapf=mapt=0;
for(int i=0;i<=x+5;++i){
add[i].clear();
ans[i].clear();
}
que.clear();
}
int main(){
int T=read();
while(T--){
x=read();y=read();z=read();
n=x+y+z;
sep();
puts("");
reset();
}
return 0;
}
|
做完啦哈哈哈